
前言
本文将从单层感知机开始逐步深入到多层感知机
神经元

神经元通过突触将神经递质传递至后一个神经元的树突
下图是神经元的电路模型

感知机
弗兰克·罗森布拉特在1957年就职于康奈尔航空实验室

$\displaystyle f(x) = \sum_{i=1}^n \omega_i x_i+b\ \ \qquad \qquad output = \begin{cases} 1 & if\ f(x)>0 \\ 0 & else \end{cases} $
输出$output$是$sgn(f(x)) $
注
感知机是一个最简单的二元分类器
下面我们假设$b=0$
假设我们有m对数据$D_m = \{(x_1, y_1),\cdots,(x_m, y_m)\}$
注
感知机通过对$D_m$多次迭代确定$\omega_i (i=1,\cdots,n)$的最终值
注意
至此
但是
如果存在一个正的常数$\gamma$和权重向量$\omega$
对所有的$i$满足$y_i \cdot(\omega\cdot x_i+b)>\gamma$ , 训练集$D_m$就被叫被做线性分隔的 , 同时 。 假设$\displaystyle R=\max_{1\leq i \leq m}\|x_i\|$ , 则错误次数$k \leq (\frac{R}{\gamma})^2$ ,
所以
多层感知机
1986年
下图是一个简单的3输入
一般来说
StackOverflow上有一个经验公式
$N_h = \frac{N_s}{\alpha (N_i+N_o)}$ : $N_s$为训练集样本数 , $\alpha$一般取2~10 , $N_i$为输入层节点数 , $N_o$为输出层节点数 , 在此经验公式上再试验调整即可 , 。

$a(\cdot)$为激活函数
说明
$h_1 = a(\sum_{i=1}^3 w^{(1)}_i[1] x_i) \quad$ $h_2 = a(\sum_{i=1}^3 w^{(1)}_i[2]x_i) \quad$ $h_3 = a(\sum_{i=1}^3 w^{(1)}_i[3]x_i) \quad$ $h_4 = a(\sum_{i=1}^3 w^{(1)}_i[4]x_i)$
$z_1 = \sum_{j=1}^4 w^{(2)}_j[1] h_j \qquad$ $ z_2=\sum_{j=1}^4 w^{(2)}_j[2]h_j$
$ y_1 = a(z_1)=f(x)[1] \qquad $ $y_2 = a(z_2)=f(x)[2]$
其中
对于偏置节点
当中间隐藏层的神经元数量趋于无穷多时
后向传播BP算法
训练模型的目的是去拟合实际情况
那么如何衡量这个误差呢
注
我们称之为期望(expected)风险
进一步的
但是我们手中只有部分的数据
我们称之为经验(empirical)风险
注
为了让权值不会过大(参数稀疏化)并减轻过拟合程度
奥卡姆剃刀原则
如无必要 : 勿增实体 , 。
$ R_{str}(f)=\frac{1}{N}\sum^N_{i=1}L(y_i,f(x_i))+\lambda J(f)$

所以
所以我们只能去求数值解
$\displaystyle w_j^1[t]=w_j^1[t] - \eta_1\frac{1}{m} \sum_{i=1}^m \frac{\partial L(y_i^*,f(x_i))}{\partial w_j^1[t]} \quad t=1,2,3,4$
$\displaystyle w_j^{(2)}[t]=w_j^{(2)}[t] - \eta_2\frac{1}{m} \sum_{i=1}^m \frac{\partial L(y_i^*,f(x_i))}{\partial w_j^{(2)}[t]} \quad t=1,2$
学习率不宜过大

注
有论文说明
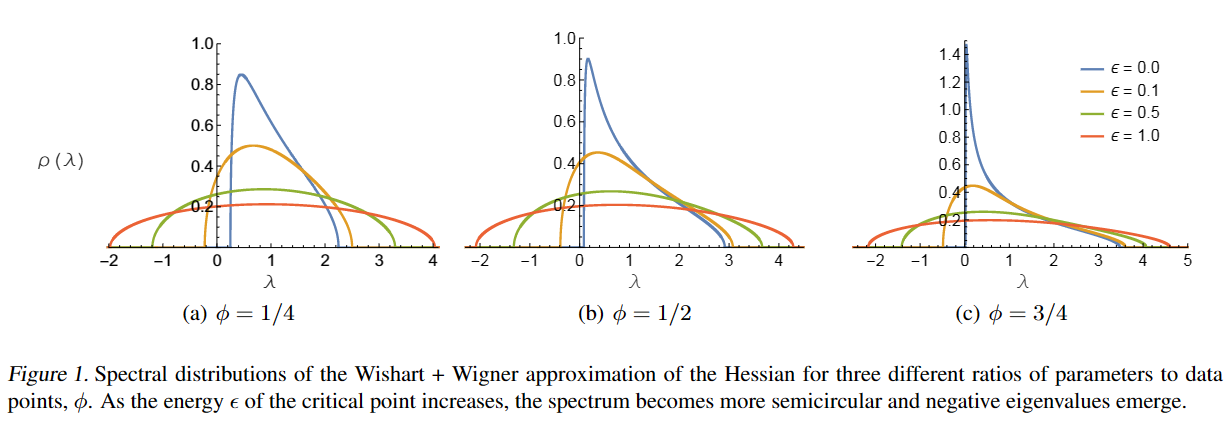
$\phi$为参数与数据量的比值
- 当Loss很大的时候
, , - 当Loss很小的时候
, , 。
大多数情况下
那么
假设其损失函数为均方损失$\displaystyle L(y^*,y)=\frac{1}{k} \sum_{i=1}^k(y_i-y^*_i)^2 \quad$
又由上文可知$\displaystyle y_i = a(z_i) \ = a(\sum_{j=1}^4 w^{(2)}_j[i] h_j)=a(\sum_{j=1}^4 w^{(2)}_j[i] a(\sum_{n=1}^3w_n^{(1)}[j]x_n))$
所以
$\displaystyle \frac{\partial L(y^*,y)}{\partial w^{(2)}_l[t]}=\frac{2}{k}\cdot (y_t-y^*_t) \frac{\partial y_t}{\partial w^{(2)}_l[t]}=\frac{2}{k}\cdot (y_t-y^*_t)\cdot \frac{\partial a(z_t)}{\partial z_t} \cdot \frac{\partial z_t}{\partial w^{(2)}_l[t]}=\frac{2}{k}\cdot (y_t-y^*_t)\cdot \frac{\partial a(z_t)}{\partial z_t} \cdot h_l$
其中
选择其他损失函数时
对第一层的梯度计算较为复杂
$\displaystyle \frac{\partial L(y^*,y)}{\partial w^{(1)}_l[t]}=\frac{2}{k}\cdot \sum_{i=1}^2 (y_i-y^*_i)\cdot\frac{\partial y_i}{\partial w^{(1)}_l[t]}$
$\displaystyle=\frac{2}{k}\cdot \sum_{i=1}^2 (y_i-y^*_i)\cdot\frac{\partial a(z_i)}{\partial z_i}\frac{\partial z_i}{\partial w^{(1)}_l[t]}$
$=\displaystyle \frac{2}{k}\cdot [(y_1-y^*_1)\cdot\frac{\partial a(z_1)}{\partial z_1}\cdot w^{(2)}_t[1]\cdot \frac{\partial h_t}{\partial w^{(1)}_l[t]}+(y_2-y^*_2)\cdot\frac{\partial a(z_2)}{\partial z_2}\cdot w_t^{(2)}[2]\cdot \frac{\partial h_t}{\partial w^{(1)}_l[t]}]$
$=\displaystyle \frac{2}{k}\cdot[(y_1-y^*_1)\cdot\frac{\partial a(z_1)}{\partial z_1}\cdot w^{(2)}_t[1] +(y_2-y^*_2)\cdot\frac{\partial a(z_2)}{\partial z_2}\cdot w_t^{(2)}[2]]\frac{\partial a(\sum_{i=1}^3 w^{(1)}_i[t] x_i)}{\partial w^{(1)}_l[t]}$
$=\displaystyle \frac{2}{k}\cdot[(y_1-y^*_1)\cdot\frac{\partial a(z_1)}{\partial z_1}\cdot w^{(2)}_t[1] +(y_2-y^*_2)\cdot\frac{\partial a(z_2)}{\partial z_2}\cdot w_t^{(2)}[2]]\cdot \frac{\partial a(\sum_{i=1}^3 w^{(1)}_i[t] x_i)}{\partial \sum_{i=1}^3 w^{(1)}_i[t] x_i}\cdot x_l $
其中$l=1,2,3 \quad t=1,2,3,4$
但是我们可以借助第二层的梯度计算结果
$\displaystyle \frac{\partial L(y^*,y)}{\partial w^{(1)}_l[t]}=[\frac{\partial L(y^*,y)}{\partial w_l^{(2)}[1]}\cdot \frac{w_t^{(2)}[1]}{h_l}+\frac{\partial L(y^*,y)}{\partial w_l^{(2)}[2]}\cdot \frac{w_t^{(2)}[2]}{h_l}]\cdot \frac{\partial a(\sum_{i=1}^3 w^{(1)}_i[t] x_i)}{\partial \sum_{i=1}^3 w^{(1)}_i[t] x_i}\cdot x_l $
将训练集中每个样本的梯度计算出来后便更新一次参数
这可以保证向
随机梯度下降Stochastic Gradient Descent
批量梯度下降Mini-Batch Gradient Descent
激活函数
接下来就是激活函数$a(\cdot)$的选择
以下是激活函数应该具有的特征
- 激活函数应该为神经网络引入非线性
, - 避免梯度弥散
( ) ( ) , , , , - 输出最好关于0对称
, , ( ) , - 激活函数应该是可微的
, - 梯度的计算不应该太复杂
,
下图是三种常用的激活函数

参数初始化
通过梯度的计算式
下图是一些初始化的方法
注
- x 趋于正无穷时
, , ; - x 趋于负无穷时
, , ; - 当一个函数既满足右饱和又满足左饱和时
, 。

$fan\_in$是指这层的输入节点数量